


 Title Index
Title Index
 Recently Changed
Recently Changed
 Page Hierarchy
Page Hierarchy
 Incomplete
Incomplete
 Tags
Tags

Introduction
When an abstract is entered it is associated with the submitter name and possibly several additional authors. The data for each author contains first name, middle initial, last name and affiliation. We put this information together to index the abstracts by author. The issue is that different people sometimes have different information about the author. For example, the affiliation could be "University of Victoria", "UVic", "UVic, Biology Department", etc. These all refer to the same affiliation but the index will not recognize that. It is possible to go into each abstract and modify this data but that is a slow process. Instead w have created a process called "Update Abstract Names" in the "Abstracts" menu.
Process
Download
When "Update Abstract People" is selected the following page will be shown:
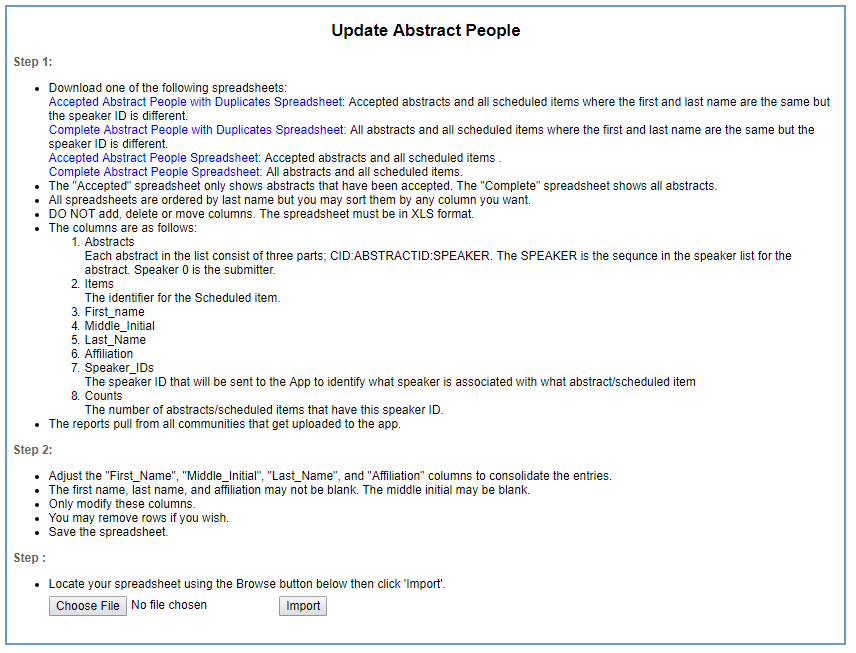
Download one of the four available files depending on how you want to work:
- The first file is people that have identified duplicates from accepted abstracts.
- The second file is people that have identified duplicates from all abstracts
- The third file is all people from accepted abstracts.
- The fourth file is all people from all abstracts.
All of these downloads will pull information from all specified communities. These can be configured by going into the edit abstract form view and toggling the appropriate switch (see page 1 of the Edit Abstract Form). Joe is also able to custom-configure the tool to run on selected CID's.
An identified duplicate is when the first and last name are the same but when the middle initial and affiliation is added create a different speaker id. For example, say we had the following entries "Robert A Brown, UVic" and "Robert Brown, University of Victoria". These two entries are obviously the same person but would create two entries as they have different middle initials and affiliations. The first two downloads show this type of record. A shortcoming of those downloads is that they will not catch instances where the names are different. For example, say we had the following entries: "Bob Brown, UVic Biology" and "Robert Brown, UVic Biology". These two entries are probably the same person. That is where the last two downloads are used.
Modification
The downloaded file will look like the following;

The columns are as follows:
- Abstracts
Each abstract in the list consist of three parts; CID:ABSTRACTID:SPEAKER. The SPEAKER is the sequence in the speaker list for the abstract. Speaker 0 is the submitter and/or primary author. - Items
The identifier for the Scheduled item. - First_name
- Middle_Initial
- Last_Name
- Affiliation
- Speaker_IDs
The speaker ID that will be sent to the App to identify what speaker is associated with what abstract/scheduled item - Counts
The number of abstracts/scheduled items that have this speaker ID.
You can then modify the data to bring those entries together. Only modify columns B through F. Do not add or delete any columns. You may delete rows if desired. To unify two speaker ID's, simply make the middle initials and affiliations the same for both rows. The system will then condense those two rows into a single speaker ID. This process can be done many times so you do not have to do them all at one sitting.
The data should look like the following;

In the above screenshot, notice that the First Name, Middle Initial, Last Name and affiliation columns have the same data for both rows. When the report is uploaded it will change the data in the abstracts and the index will have the same speaker ID for both abstracts. All other columns have not been changed.
When all editing is complete save the spreadsheet.
Upload
The final step is to upload the file:
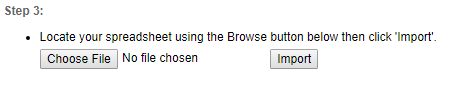
Click on "Choose File", select the spreadsheet saved in the previous step, and click "Import". If there are any errors in the file you will be informed and will need to correct them before attempting to import again.
Suggested Use
As this can be a large task it is suggested that it be done in several parts and as soon as practical. Every time you work on this task you must download a new spreadsheet. Most of the time you will be working with the first two spreadsheets as they show the easily identified issue. Close to the conference it is best to have one final push where the third spreadsheet (all accepted abstracts/scheduled items) is used. This will enable us to catch as many duplicate entries as possible.